Création d'une infrastructure sécurisée
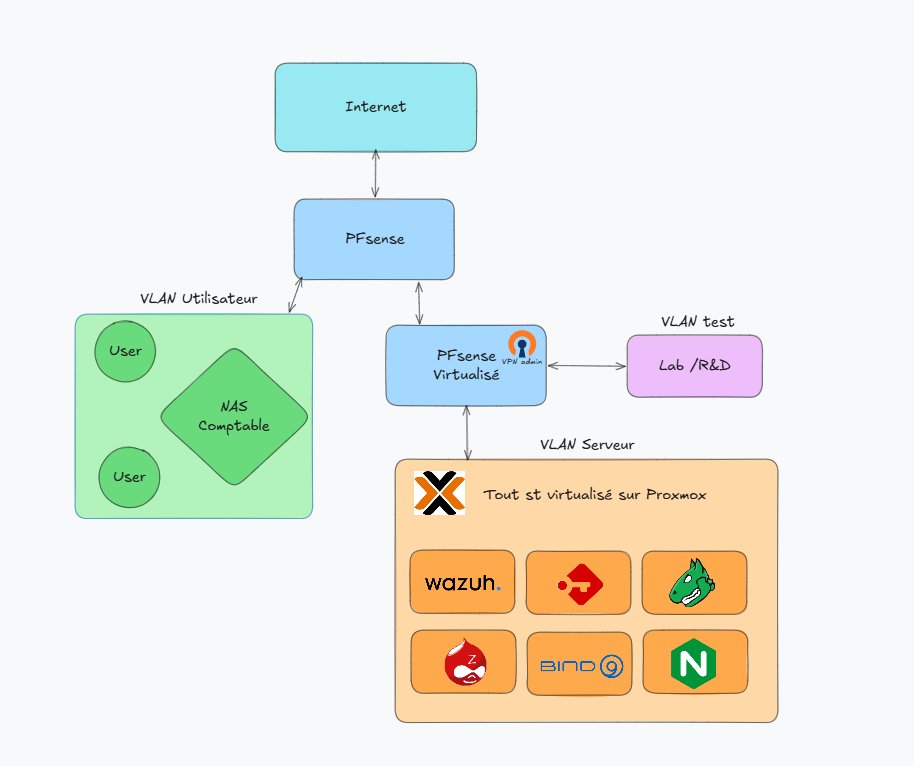
Architecture de l'infrastructure : 3 VLAN (Utilisateur, Lab-R&D, Production), pfSense, Proxmox et services associés.
// En une phrase
Transformer en 12 mois l'environnement d'une TPE composé d'un pare-feu et d'un NAS en une infrastructure complète à 35 machines virtuelles, dont un SOC qui a ensuite été commercialisé en offre de service auprès des clients de l'entreprise.
Contexte et présentation
Dans le cadre de ma première alternance chez Valesys, entre septembre 2023 et août 2024, j'ai travaillé sur l'infrastructure interne d'une entreprise d'environ quinze personnes. À mon arrivée, accompagné d'un autre alternant, nous avons découvert un environnement extrêmement limité : un pare-feu et un NAS, sans gestion des identités, sans segmentation réseau, sans environnement de test, ni outils de supervision. L'ensemble des utilisateurs partageait un réseau unique, sans distinction des usages ni contrôle des flux. C'est dans ce contexte que j'ai construit, en quasi-totale autonomie technique, une infrastructure complète et sécurisée.
Objectifs, enjeux et redéfinition du besoin
La demande initiale consistait à déployer un SOC. Après une phase d'analyse de l'existant, j'ai rapidement identifié que cette demande reposait sur des fondations insuffisantes : monter un dispositif de détection sur une infrastructure sans segmentation, sans gestion d'identité et sans supervision aurait produit un produit de façade plutôt qu'un véritable outil de sécurité. J'ai donc pris l'initiative, en concertation avec mon responsable, de redéfinir les priorités du projet : construire d'abord une infrastructure sécurisée et cohérente, puis seulement ensuite y greffer un mécanisme avancé de détection.
L'enjeu était double. Pour Valesys, il s'agissait d'améliorer immédiatement la posture de sécurité tout en posant les bases d'un SOC réellement pertinent, qui pourrait éventuellement être commercialisé auprès des clients de l'entreprise. Pour moi, il s'agissait de conduire un projet de bout en bout sans encadrement technique senior, dans un environnement où chaque décision avait un impact réel et durable.
Les risques principaux étaient triples. Un risque technique : faire des choix d'architecture difficilement réversibles avec une expérience limitée. Un risque opérationnel : casser l'existant pendant la migration, en privant les utilisateurs d'outils dont ils dépendaient. Un risque de continuité enfin : nous étions deux alternants, et tout ce que nous bâtirions devait pouvoir être maintenu après notre départ par d'autres profils.
Étapes de réalisation
Concevoir la segmentation, le pare-feu et l'accès distant
La première étape, qui conditionnait toutes les suivantes, a été la refonte complète du réseau. J'ai conçu une segmentation en trois VLAN aux finalités distinctes : un VLAN Utilisateur pour les postes de travail, un VLAN Lab-R&D pour les environnements de test isolés, et un VLAN Production pour les serveurs critiques exposés à des services métier. Ce découpage permettait de contenir les incidents par zone et de définir des politiques de filtrage inter-zone explicites.
Le pare-feu pfSense a été configuré avec une politique restrictive par défaut : tout flux non autorisé explicitement était bloqué. Les règles entre VLAN ont été définies en partant des besoins fonctionnels recensés auprès des utilisateurs, puis affinées par observation des logs sur les premières semaines de production. L'accès distant a été assuré par un service OpenVPN hébergé directement sur pfSense côté Production, ce qui m'évitait d'exposer une machine d'administration sur Internet et concentrait l'authentification VPN sur l'équipement le plus surveillé de l'infrastructure.
Cette première étape m'a confronté à une difficulté pratique récurrente : écrire des règles de filtrage fines coûte du temps, mais une règle "any/any" en production est un piège qui revient toujours en dette technique. C'est exactement le réflexe que je pratique aujourd'hui chez Paritel, où la rigueur sur la matrice de flux est encore plus critique.
Déployer Proxmox, puis évoluer vers un cluster Ceph résilient
Une fois le réseau prêt, j'ai déployé l'hyperviseur Proxmox VE sur un serveur Dell 1U d'occasion récupéré en octobre 2023. Cet hyperviseur unique a porté toute l'infrastructure pendant les premiers mois : DNS interne, supervision, services applicatifs, machines de test. Le Proxmox Backup Server a été déployé en parallèle, avec déport des sauvegardes vers le NAS existant pour ne pas dépendre du serveur unique.
Deux incidents ont rapidement justifié une évolution. D'abord une saturation du datastore par les logs ingérés par la stack de supervision : le Proxmox a crashé pendant une nuit, et j'ai dû redémarrer le serveur en mode single-user Linux, identifier la VM en cause, supprimer une VM de test pour libérer de l'espace et reconfigurer la politique de rétention des logs. Ensuite une coupure de courant qui a rendu l'ensemble des services indisponibles pendant plusieurs heures, faute de redondance matérielle. Ces deux incidents ont directement servi d'arguments budgétaires pour obtenir un second serveur.
En mars 2024, un second nœud Proxmox a été obtenu, hébergé en cloud, avec 2 To utiles par serveur. J'ai déployé un cluster Ceph à 2 nœuds en miroir avec mon collègue alternant, permettant la résilience du stockage et la haute disponibilité des VM critiques. Au pic d'activité, l'infrastructure hébergeait une quinzaine de VM en production et une vingtaine de VM de pré-production et de lab.
DNS interne, supervision, reverse proxy, gestion des secrets
Les services applicatifs ont été déployés dans un ordre dicté par les priorités opérationnelles, pas par la facilité de mise en œuvre. Zabbix a été déployé en premier car la supervision des serveurs et du réseau était mon besoin le plus critique à court terme : je ne connaissais pas encore les enjeux de l'entreprise côté utilisateur, et il fallait d'abord stabiliser le socle technique avant d'ajouter des couches métier. Passbolt est arrivé plus tard, quand nous avons commencé à structurer la sécurité côté utilisateurs.
Le DNS interne a été assuré par Bind9 avec DNSSEC activé, pour garantir l'intégrité des résolutions internes. La configuration de zone signée ressemblait à ceci, avec une rotation manuelle des clés au début, puis automatisée par la suite :
// /etc/bind/named.conf.local
zone "valesys.lan" {
type master;
file "/etc/bind/db.valesys.lan.signed";
auto-dnssec maintain;
inline-signing yes;
key-directory "/etc/bind/keys";
allow-query { internal-net; };
};Le reverse proxy Nginx centralisait l'accès aux interfaces web internes (Zabbix, Passbolt, Proxmox, etc.). Tous les certificats X.509 étaient auto-signés par une autorité de certification interne que j'avais générée pour l'occasion, plutôt que de m'appuyer sur Let's Encrypt qui ne fonctionne pas pour des services internes non exposés à Internet. L'import de cette autorité dans le magasin de confiance des postes Debian se faisait en deux commandes :
# Sur chaque machine cliente Debian
sudo cp valesys-internal-ca.crt /usr/local/share/ca-certificates/
sudo update-ca-certificatesPour industrialiser cette opération sur tous les nouveaux serveurs déployés, j'ai écrit un script d'automatisation portatif qui prenait en charge l'import de la CA, l'application des règles de durcissement de base et la configuration des outils de supervision. Ce script est mentionné dans ma compétence Tooling & Scripting comme l'un des outils que j'ai conçus dans une logique de réutilisabilité.
Passbolt a été déployé dans un second temps, avec une vingtaine de comptes : un compte par collaborateur de l'entreprise, plus un compte de service dédié aux techniciens qui hébergeait les informations sensibles côté client (accès clients, secrets d'infrastructure). Cette séparation a été ma première véritable confrontation à la gestion d'identités en environnement multi-utilisateurs, exercice plus subtil qu'il n'y paraît : décider qui voit quoi, comment révoquer un accès quand un collaborateur part, comment gérer un compte de service partagé sans diluer la responsabilité.
Déployer Wazuh comme socle de détection, avec une stack ELK en arrière-plan
Une fois l'infrastructure stabilisée, j'ai abordé la mission initiale : déployer un SOC. Le choix s'est porté sur Wazuh plutôt que sur une stack ELK pure, car Wazuh embarque déjà la stack ELK comme back-end tout en apportant nativement les agents, les decoders et le moteur de règles de corrélation. À l'inverse, une stack ELK seule aurait demandé de tout construire à la main : agents, parsers, règles, dashboards. J'ai effectivement tenté une approche ELK pure en R&D, qui était techniquement viable mais bien plus coûteuse à mettre en œuvre dans le temps disponible. Ce projet R&D a été abandonné au profit de Wazuh, ce qui a été le bon arbitrage pour le contexte.
Sur Wazuh, j'ai mis en place plusieurs règles de corrélation custom, en complément des règles fournies par défaut. Ces règles couvraient des cas spécifiques au contexte Valesys (alerte sur connexion VPN inhabituelle, détection de modifications de fichiers critiques sur les serveurs Proxmox, surveillance des authentifications Passbolt). Une partie de ces règles devait être évaluée et ajustée avec les clients lors de la commercialisation du SOC, ce qui a été fait après mon départ.
La complétion par Graylog et Grafana permettait des visualisations avancées et des tableaux de bord opérationnels. La stack complète ingérait les logs depuis pfSense, les serveurs Proxmox, les VM applicatives, et les postes utilisateurs équipés d'agents Wazuh.
Organisation et acteurs
Ce projet a été mené par mon collègue alternant et moi-même, avec une validation ponctuelle d'un responsable sans compétences techniques approfondies. Cette configuration nous a placés dans une autonomie technique inhabituelle pour des alternants : pas de senior pour valider une commande critique avant exécution, pas d'architecte pour challenger un choix de stack, pas de pair pour relire une configuration sensible. Nous nous validions mutuellement avant chaque décision structurante.
La dynamique en binôme a été un facteur clé de réussite. Nous nous répartissions les sujets selon nos affinités (j'avais une plus grande appétence pour la sécurité et la conception, lui pour certaines parties opérationnelles), mais nous nous obligions à passer du temps sur les sujets de l'autre pour éviter les bus factor : aucun de nous deux ne devait être le seul à savoir comment redémarrer un service ou réparer une VM.
Les utilisateurs internes (une quinzaine de collaborateurs) ont été des interlocuteurs réguliers, notamment pour la phase de déploiement de Passbolt qui touchait directement leur quotidien. Apprendre à expliquer un changement technique à un public non-technique a été l'un des apprentissages collatéraux les plus précieux de cette mission.
Résultats
Pour Valesys, l'entreprise est passée d'un environnement informatique limité à un pare-feu et un NAS à une infrastructure complète à 35 machines virtuelles, avec segmentation réseau, supervision en temps réel, gestion centralisée des secrets, sauvegardes automatisées et SOC opérationnel. Le SOC issu de ce projet a ensuite été commercialisé en offre de service auprès des clients de l'entreprise, transformant ce qui aurait pu être un produit interne de surface en un vrai produit commercial. C'est probablement le meilleur indicateur de la qualité du travail réalisé : ce que nous avons construit a été jugé suffisamment robuste pour être vendu à des tiers.
Pour moi, le résultat a été un saut de maturité technique difficilement quantifiable, mais bien réel. J'ai acquis une confiance opérationnelle qu'aucun cours ne donne : la certitude que face à un problème inconnu, je trouverai un chemin parce que je l'ai déjà fait sur des sujets très différents. J'ai aussi consolidé des compétences sur Proxmox et Ceph qui me servent aujourd'hui chez Paritel comme sur mes projets personnels, et j'ai compris dans la pratique pourquoi la sécurité doit être pensée dès la conception et non ajoutée après coup.
Lendemains du projet
J'ai laissé à mon départ une série complète de documentation sur les choix d'infrastructure et le fonctionnement détaillé de chaque machine virtuelle. Mon objectif était simple : que cette infrastructure ne soit pas laissée à l'abandon par manque de transmission. Cette documentation couvrait les schémas réseau, la configuration de pfSense, la procédure de basculement Ceph, les politiques de sauvegarde PBS, et les playbooks pour les opérations de maintenance courantes. La passation s'est faite avec le nouvel arrivant en charge de prendre la suite, et le binôme alternant avec qui j'ai construit l'infrastructure est resté en poste pour assurer la continuité.
L'infrastructure a continué d'évoluer après mon départ. Un Active Directory a été déployé pour structurer la gestion d'identité côté utilisateurs, ce qui n'avait pas pu être fait pendant mon contrat faute de temps. Le SOC a été étendu à plusieurs clients commerciaux de Valesys, qui louent désormais la capacité de supervision développée pendant ma mission. Des nœuds Proxmox supplémentaires ont été déployés pour absorber la croissance d'activité. Ces informations me viennent directement d'un ami et ancien collègue qui travaille encore chez Valesys, ce qui me permet de continuer à suivre l'évolution de l'infrastructure malgré mon départ.
Aujourd'hui chez Paritel, je travaille à une échelle radicalement différente : l'équipe Sécurité & Réseaux opère trois clusters ELK distincts (un client, un personnel, un de lab) qui ingèrent en moyenne 700 000 logs par jour, en provenance d'une grande diversité de sources (gestionnaire de mots de passe 1Password, reverse proxies HAProxy, pare-feux Juniper, Fortinet, Palo Alto, sondes IDS, trafic client par JFlow sur les routeurs externes, et de nombreux composants tiers de sécurité). Cette exposition à une échelle opérateur a profondément fait évoluer ma compréhension de ce qu'est un SOC mature.
Avec cette expérience, je referais aujourd'hui certains choix différemment chez Valesys. Je structurerais davantage les pipelines Logstash dès le départ, j'investirais plus tôt dans les politiques de rétention par index, je découperais le cluster ELK en plusieurs nœuds dédiés plutôt que tout sur une seule VM, et j'industrialiserais davantage la création de règles Wazuh via du code versionné plutôt que via l'interface graphique. Ce qui prouve que cette compétence n'est jamais figée : chaque nouvelle expérience reconfigure rétrospectivement les précédentes.
Regard critique
Mes apports concrets au projet ont été triples. D'abord le recadrage initial de la mission : refuser de partir directement sur le SOC pour analyser ce qui manquait en amont a été la décision la plus structurante de tout le projet, et elle a été prise dans les deux premières semaines. Ensuite la conception bout en bout de l'architecture : VLAN, choix d'hyperviseur, dimensionnement du stockage, choix du SIEM, ces décisions techniques structurantes ont été prises en autonomie. Enfin l'industrialisation à travers les scripts d'automatisation et la documentation, qui ont permis à l'infrastructure de survivre à mon départ.
Ma valeur ajoutée mesurable est dans le passage du "produit interne" au "produit commercialisable". Sans la phase d'infrastructure préalable, le SOC initialement demandé aurait été un produit de surface, jamais commercialisable. En posant les fondations techniques avant de déployer la couche détection, j'ai transformé une mission de quelques mois en un actif commercial pour l'entreprise, ce qui dépasse largement le périmètre attendu d'un alternant.
Mes enseignements personnels sont nombreux. L'autonomie sans filet a confirmé que je sais avancer seul face à un problème inconnu, ce qui n'était pas garanti avant cette mission. L'importance des fondations techniques, qu'on a tendance à sacrifier pour aller vite, est devenue pour moi un principe non négociable : on ne pose pas une couche avancée sur des fondations bancales, sinon on construit du fragile. Et la sécurité dès la conception ("security by design") n'est plus pour moi une formule théorique : c'est devenu un réflexe pratique que j'applique à tous mes projets, professionnels ou personnels.
Avec le recul, je vois aussi les limites de cette expérience. L'absence d'encadrement technique senior, qui a été un accélérateur d'autonomie, a aussi été un frein à la rigueur méthodologique : personne ne nous a appris à structurer une revue de configuration, à formaliser un post-mortem d'incident, à documenter une décision d'architecture (ADR). Ces pratiques, je les ai découvertes seulement plus tard chez Paritel, et je sais aujourd'hui que je les aurais introduites bien plus tôt si on me les avait montrées. C'est précisément pour cela que je cherche désormais des contextes professionnels où je peux apprendre au contact de profils techniques expérimentés.
Compétences rattachées
Ce projet a mobilisé l'essentiel de mes compétences techniques et humaines. Sur le volet technique, il illustre principalement la Virtualisation (Proxmox, cluster Ceph, PBS), l'Administration Réseau (segmentation VLAN, pfSense, VPN OpenVPN) et la Configuration Système (Bind9 DNSSEC, Wazuh, Nginx, Zabbix, Passbolt). Sur le volet humain, il met en avant la Gestion de projet conduite en autonomie sur 12 mois et la capacité à Faire preuve d'initiative, dont le recadrage initial de la mission est probablement la meilleure illustration.