Sonde IDS conteneurisée
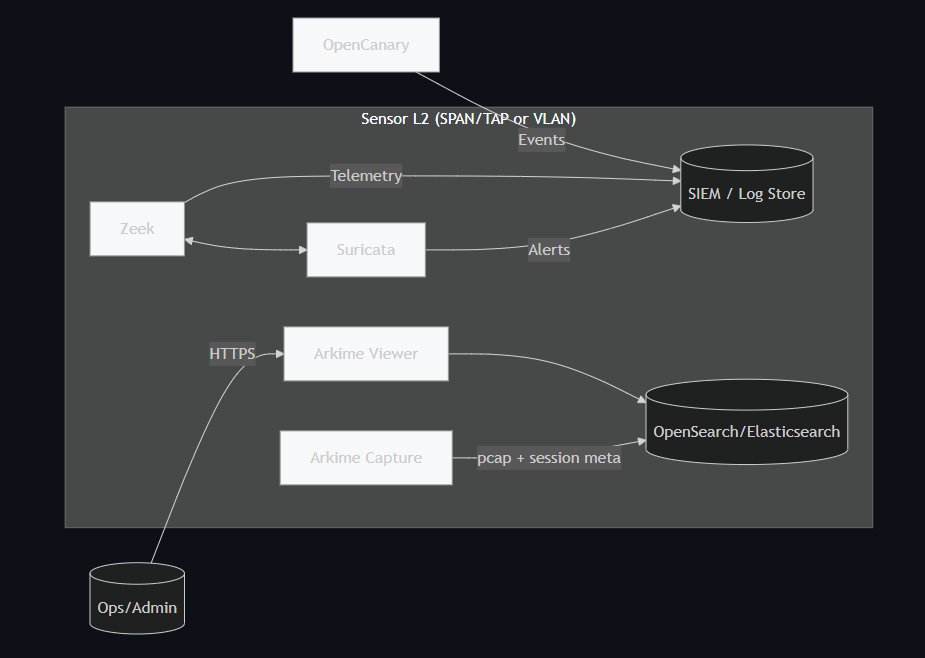
Architecture conteneurisée : Suricata, Zeek, Arkime (init / capture / viewer), OpenCanary, et OpenSearch en back-end, raccordés à un réseau macvlan dédié à la capture.
// En une phrase
Transformer une frustration opérationnelle, déployer manuellement plusieurs sondes IDS identiques sur des VM, en un scaffold Docker open source publié sur GitHub, qui ramène le temps de déploiement de 1 à 2 heures par sonde à 10 à 20 minutes de configuration, et qui sert de référence à au moins un autre praticien en production.
Contexte et présentation
Docker-IDS-Sensor est un projet personnel open source démarré en octobre 2025, qui réunit quatre outils de sécurité réseau dans une stack Docker reproductible : Suricata pour la détection par signatures, Zeek pour la télémétrie réseau riche, Arkime pour la capture full-packet avec indexation des sessions, et OpenCanary comme honeypot bas niveau. Le tout s'appuie sur un back-end OpenSearch/Elasticsearch pour le stockage et la recherche des données.
Le projet est explicitement positionné comme un PoC / lab scaffold pour praticiens à l'aise avec Docker et la configuration de ces outils. Ce n'est pas un produit clé en main, c'est un raccourci concret pour quiconque doit monter une sonde réseau open source sans repartir de zéro à chaque fois.
Origine, objectifs et enjeux
L'origine du projet est très concrète, et c'est ce qui en fait sa pertinence. Dans mon rôle chez Paritel, j'ai eu à déployer plusieurs sondes IDS sur des machines virtualisées distinctes. À chaque sonde, le même rituel : provisionner une VM, installer un OS minimal, ajouter les dépôts, installer et configurer Suricata, configurer la capture, gérer les interfaces, vérifier que le trafic remontait, refaire la même chose pour Zeek, etc. Ce processus durait une à deux heures par sonde, pour produire à chaque fois exactement la même chose, à des variables d'environnement près (interfaces, VLAN, IP de management).
J'ai alors envisagé de conteneuriser les composants, en partant du principe que Docker existe précisément pour résoudre ce genre de répétition. Mais les images publiques disponibles posaient deux problèmes : elles n'étaient pas à jour, et faire fonctionner les composants individuellement en conteneur exigeait à chaque fois de résoudre les mêmes problèmes (capture promisc, capabilities réseau, persistance des logs, raccord à OpenSearch). Plutôt que de répéter cette résolution à chaque besoin, j'ai décidé sur mon temps personnel de construire un scaffold réutilisable qui résoudrait ces questions une fois pour toutes.
L'enjeu était double. Pour moi, gagner du temps sur tous les déploiements futurs et capitaliser proprement sur l'expérience acquise. Pour la communauté, publier un travail qui pourrait servir à d'autres praticiens cyber confrontés au même rituel répétitif. Les risques étaient ceux classiques d'un projet open source amateur : produire quelque chose de bancal qui décevrait, ou pire, qui induirait en erreur. C'est pourquoi j'ai investi un effort significatif dans la documentation et dans la qualité du README, plus que strictement nécessaire pour mon usage personnel.
Étapes de réalisation
Sélectionner les outils, l'OS de base et le modèle de réseau Docker
La première étape a été un cadrage technique précis, en m'appuyant sur mes déploiements individuels précédents. J'avais déjà déployé Suricata, Zeek, Arkime et OpenCanary séparément hors Docker, ce qui m'a évité de découvrir leurs particularités en route. J'ai retenu ces quatre outils parce qu'ils se complètent fonctionnellement sans se concurrencer : Suricata fait de la détection par signatures, Zeek produit des logs structurés riches, Arkime conserve les PCAP indexés, OpenCanary apporte des données issues d'un honeypot.
Pour l'OS de base, j'ai choisi Alpine Linux. C'est une habitude personnelle (Alpine est léger, son écosystème de paquets est suffisant, son empreinte de surface d'attaque est minimale), mais le projet reste compatible avec n'importe quelle base Debian-like en cas de besoin. Le choix n'est pas dogmatique.
Côté réseau Docker, j'ai retenu un modèle macvlan qui permet d'attacher la sonde directement sur le segment surveillé (SPAN/TAP, VLAN dédié), tout en gardant le management isolé. Le réseau macvlan se crée en une commande, qui est exécutée par un script bootstrap pour faciliter l'initialisation :
PARENT_IF=enp3s0
SUBNET=192.168.50.0/24
GATEWAY=192.168.50.1
NET_NAME=ids_macvlan
docker network create -d macvlan \
--subnet="$SUBNET" --gateway="$GATEWAY" \
-o parent="$PARENT_IF" "$NET_NAME"L'alternative network_mode: host reste supportée et documentée, pour les contextes où macvlan n'est pas adapté (lab simple sur un poste de dev par exemple).
Structurer le projet en quatre composants indépendants
L'architecture du dépôt suit un principe simple : un dossier par outil, chaque dossier autonome avec son propre Dockerfile, son docker-compose.yml et sa configuration. Cette modularité permet à un utilisateur de n'utiliser que ce dont il a besoin : déployer Suricata seul, ou Suricata+Zeek, ou la stack complète, sans devoir tout charger.
Docker-IDS-Sensor/
├─ arkime-docker/ # Arkime : init, capture, viewer + config.ini
├─ opencanary-docker/ # OpenCanary + .opencanary.conf
├─ suricata-docker/ # Suricata + suricata.yaml + local.rules
├─ zeek-docker/ # Zeek + scripts/ + zeekctl.cfg
├─ init-and-start_IDS_Honeypot.sh # Bootstrap macvlan + démarrage stack
└─ README.mdArkime se découpe en trois conteneurs (init, capture, viewer) car c'est l'architecture native de l'outil. Le conteneur init prépare les index OpenSearch lors du premier démarrage, capture fait la capture continue, et viewer expose l'interface web. Cette séparation suit les recommandations officielles d'Arkime et facilite le scaling horizontal du capture si nécessaire.
Résoudre la question des versions à jour des outils
Le problème principal avec les images publiques disponibles était que les versions étaient en retard par rapport aux releases officielles des projets upstream. Pour Suricata et Zeek notamment, les images Docker Hub étaient parfois six mois en retard sur la dernière version stable, ce qui pose un vrai problème en sécurité où les nouvelles détections sont régulièrement ajoutées.
J'ai donc choisi de compiler les outils depuis les sources dans des Dockerfiles multi-stage Alpine. Cette approche permet d'avoir toujours la dernière version au moment du build, au prix d'un temps de construction plus long (compilation initiale de quelques minutes par outil). Pour Suricata, cela impliquait de gérer les dépendances système (libpcap, hyperscan pour la performance des règles, libmagic, jansson). Pour Zeek, des dépendances plus volumineuses (libpcap, OpenSSL, ZeroMQ).
L'autre point critique a été la capture réseau dans un conteneur. Sans capabilities spécifiques, un conteneur ne peut pas mettre une interface en mode promiscuous, donc ne voit aucun trafic. Le réflexe naïf est de lancer le conteneur en --privileged, ce qui marche mais ouvre largement la surface d'attaque. La bonne approche est de donner uniquement les capabilities nécessaires :
services:
suricata:
cap_add:
- NET_ADMIN
- NET_RAW
- SYS_NICE
network_mode: host # ou attachement à un macvlan dédiéSans ces capabilities, les conteneurs démarrent sans erreur mais ne capturent rien, ce qui est un faux positif silencieux particulièrement piégeant : tout semble fonctionner, mais Suricata ne voit aucun paquet et donc ne génère aucune alerte. Ce piège est documenté explicitement dans le README pour éviter à d'autres utilisateurs de tomber dedans.
Automatiser la création du réseau macvlan et le démarrage de la stack
Pour réduire le temps de déploiement, j'ai écrit un script shell init-and-start_IDS_Honeypot.sh qui prend en charge le bootstrap complet de la sonde. Il crée le réseau macvlan selon les paramètres locaux, démarre les conteneurs dans le bon ordre (OpenSearch en premier, puis Arkime-init, puis les composants de capture), et fait un diagnostic basique pour vérifier que tout est opérationnel.
L'utilisateur peut soit utiliser ce script tout-en-un, soit lancer chaque composant individuellement avec un simple docker compose up -d dans le dossier correspondant. Les deux modes sont documentés dans le README pour s'adapter à des cas d'usage différents (lab rapide vs déploiement plus structuré).
Écrire un README de qualité avant de communiquer publiquement
Le README représente probablement 30 % du temps total que j'ai passé sur ce projet. Je le considère comme le composant le plus important : un outil de sécurité que personne ne comprend ne sera jamais utilisé. Le README couvre la description, l'architecture, les prérequis, le quickstart, une checklist de configuration par outil, les opérations courantes, les notes de hardening, le troubleshooting, et une FAQ.
J'ai rédigé l'intégralité du README en anglais pour maximiser la portée potentielle. Une fois la v1 stable, j'ai annoncé le projet sur trois canaux : GitHub (publication publique), Keybase dans ma communauté technique, et X (Twitter) en post public. La communication est restée modeste, sans relayage par des comptes influents, ce qui explique en partie la traction limitée de la publication.
Organisation et acteurs
Ce projet est mené intégralement en solo, sur mon temps personnel, sans encadrement ni co-contributeur. C'est à la fois sa force (liberté totale de conception, pas de compromis) et sa limite (pas de revue de code, pas de challenge sur les choix d'architecture).
Le principal acteur extérieur est un ami pentester, membre de ma communauté technique sur Keybase, qui a testé le déploiement complet en suivant uniquement le README. Son retour a été précieux à deux niveaux : il a confirmé que le déploiement était reproductible par un tiers (pas seulement par moi qui ai écrit le code), et il a relevé quelques points peu clairs dans la documentation que j'ai ensuite ajustés. Il est resté utilisateur silencieux sur la partie IDS principale mais utilise activement le composant OpenCanary dans l'infrastructure de son entreprise, ce qui est le meilleur signal possible : il l'utilise en vrai, pas juste pour faire plaisir à un copain.
Au-delà de cet utilisateur identifié, le projet existe publiquement avec 2 stars sur GitHub à ce jour, ce qui reste modeste mais réel. Je ne dispose pas de statistiques sur les utilisateurs anonymes qui auraient cloné le dépôt sans laisser de trace.
Résultats
Pour moi, le résultat principal est un scaffold réutilisable qui élimine la répétition que je subissais à chaque besoin de nouvelle sonde. Là où un déploiement manuel coûtait une à deux heures par sonde, le scaffold ramène ce temps à 10 à 20 minutes de configuration (interfaces, IP de management, paramètres macvlan) plus quelques minutes de build et démarrage des conteneurs. Sur un déploiement de quatre sondes complètes, le gain cumulé approche une heure de travail effectif sur quelques heures de coût total.
Pour la communauté, le résultat est plus modeste mais réel : un dépôt public, documenté, fonctionnel, qui sert de référence à au moins un autre praticien en production sur le volet OpenCanary, et qui pourrait éventuellement aider d'autres profils cyber confrontés à la même répétition que moi. La traction publique reste limitée (2 stars, 0 forks visibles, peu de visibilité après les annonces Twitter/Keybase), mais c'est un point que j'aborde honnêtement dans le regard critique plus bas.
Lendemains du projet
Après la publication de la v1 fin octobre 2025, j'ai continué à pousser des commits sur la branche main pour stabiliser l'ensemble : ajustements de la documentation suite aux retours de l'ami pentester, correction de petits problèmes de configuration relevés en test, amélioration du script de bootstrap. La communication initiale s'est faite sur Twitter et Keybase, sans relais notable. C'est aussi à cette période que le composant OpenCanary a été repris en production réelle par mon contact pentester.
Le projet est ensuite entré en pause active par manque de temps. La combinaison du Mastère ESIEA + de l'alternance Paritel n'a pas laissé suffisamment de bande passante pour pousser le projet plus loin pendant cette période. J'ai conservé une volonté claire de le reprendre et de le pousser à plus grande échelle, mais sans forcer un rythme intenable qui aurait fini par dégrader la qualité du code. C'est un arbitrage honnête entre charges professionnelles, charge scolaire et projets personnels.
Le projet est encore vivant et sera repris activement dès la fin de mes études en juillet 2026. La roadmap envisagée à ce stade tourne autour de plusieurs axes : passer la configuration macvlan en mode par défaut (le mode network_mode: host deviendrait l'option de repli), publier un build multi-architecture incluant ARM pour permettre le déploiement sur des Raspberry Pi en sonde de proximité, intégrer un flux MISP pour alimenter automatiquement Suricata avec des indicateurs de compromission communautaires, et mettre en place un pipeline GitHub Actions pour automatiser les builds et tests à chaque push.
À plus long terme, l'idée est de transformer ce qui est aujourd'hui un scaffold de lab en quelque chose de plus proche d'un outil "prêt à déployer" pour des praticiens qui n'ont pas le temps de tout reconfigurer manuellement. Ce serait un changement de positionnement assumé, du PoC au produit.
Regard critique
Mes apports concrets au projet sont triples. D'abord la conception architecturale : choix des quatre outils complémentaires, choix d'Alpine, choix du modèle macvlan, structuration modulaire par composant. Ensuite le travail de compilation depuis les sources dans des Dockerfiles multi-stage propres, qui résout le vrai problème opérationnel (versions à jour) et qui n'avait pas de solution toute faite. Enfin la documentation, qui est le composant le plus chronophage mais aussi celui qui détermine si le projet est utilisable par d'autres ou non.
Ma valeur ajoutée mesurable est le gain de temps concret sur tout déploiement de sonde IDS, à la fois pour moi et pour quiconque adoptera le scaffold. C'est aussi la démonstration qu'un alternant peut produire du code open source publié qui n'est pas une copie de tutoriel, mais une vraie réponse à un problème opérationnel concret. Cette légitimité, même modeste, est précieuse dans une trajectoire orientée vers la contribution open source.
Mes enseignements personnels sont nombreux, et certains sont inconfortables. Le plus marquant est sans doute la confirmation que publier ne suffit pas à être adopté : malgré un README soigné, des choix techniques défendables et une vraie utilité opérationnelle, le projet n'a pas décollé en termes de visibilité. La traction communautaire dépend largement de relais que je n'avais pas et que je n'ai pas cherché à construire. C'est une leçon importante pour les projets open source à venir : la communication est aussi importante que le code, et un projet qui n'est pas vu n'existe pas socialement. Le second enseignement est la discipline du README : ce n'est pas un accessoire qu'on bâcle à la fin, c'est l'interface principale entre le projet et le monde. Tout le temps investi sur la documentation a été du temps bien dépensé.
Avec le recul, je vois aussi les limites de ce projet. Le fait d'être seul sur la conception m'a privé de challenges techniques que j'aurais bénéficié à recevoir : pas de revue de code, pas de discussion sur les choix d'architecture, pas de confrontation à des cas d'usage que je n'ai pas anticipés. La pause active du projet pendant l'hiver 2025-2026 est aussi une faiblesse assumée : un projet open source vit ou meurt par sa régularité, et plusieurs mois de silence reduisent mécaniquement les chances qu'un nouvel utilisateur s'y intéresse. La reprise prévue à la fin de mes études sera l'occasion de corriger cela.
Compétences rattachées
Ce projet mobilise une combinaison de compétences techniques et humaines. Sur le volet technique, il illustre principalement la Virtualisation dans son aspect conteneurisation avancée (Docker, macvlan, capabilities), le Tooling & Scripting (passage d'un script personnel à un scaffold publié réutilisable), la Configuration Système (Suricata, Zeek, Arkime, OpenCanary, OpenSearch) et Git (utilisation publique d'un dépôt GitHub avec 35 commits sur main). Sur le volet humain, il met en avant la capacité à Faire preuve d'initiative (transformer une frustration opérationnelle en projet personnel construit) et l'Esprit de partage (publier en open source plutôt que de garder pour soi).