Script de setup personnel
// En une phrase
Passer d'un poste Linux vierge à un environnement de travail entièrement configuré et durci en moins d'une heure, grâce à un script Python idempotent qui automatise cinq couches d'installation et qui transforme ma propre discipline de travail en code versionné.
Contexte et présentation
Tout technicien qui travaille régulièrement sur plusieurs machines finit par se poser la même question : combien de temps faut-il pour retrouver un environnement de travail pleinement opérationnel sur une nouvelle installation ? Pour moi, la réponse était trop longue. J'ai donc développé un script Python d'installation automatisée qui me permet de passer d'un système Linux vierge à un poste entièrement configuré, avec mes outils, mes politiques de durcissement et mes préférences personnelles, en moins d'une heure et en quelques commandes.
Le projet est hébergé sur mon dépôt GitHub mais en mode privé. Mes dotfiles contiennent en effet des configurations personnelles que je ne souhaite pas exposer publiquement (paramètres de proxy, raccourcis spécifiques, références à des hôtes de mon homelab). Le script reste néanmoins facilement adaptable à un usage en entreprise en modifiant deux ou trois variables : c'est exactement le type d'outil qui peut servir aussi bien sur poste personnel que dans un contexte professionnel maîtrisé.
Genèse, objectifs et enjeux
Le projet a commencé sous forme de petites briques disparates en mi-2024, sans architecture claire : quelques alias shell sauvegardés, un script d'installation de paquets, des dotfiles éparpillés. Le vrai déclic est arrivé début 2025, après avoir vu une vidéo de la chaîne Dinkii qui présentait une approche structurée de l'automatisation d'environnement de travail. Cela m'a donné le cadre méthodologique qui manquait à mes briques personnelles, et m'a poussé à transformer ces fragments en un véritable outil cohérent.
L'objectif est simple à formuler mais structurant à atteindre : ne plus jamais perdre de temps à reconfigurer un poste depuis zéro. Que ce soit après une réinstallation, sur une nouvelle machine, ou dans un lab éphémère, je veux être opérationnel le plus vite possible, avec un environnement identique à celui que je connais et qui me convient.
L'enjeu est triple. Un enjeu d'efficacité d'abord : un environnement mal configuré ou incomplet ralentit, distrait et génère des frictions inutiles. Un enjeu de cohérence ensuite : avoir le même environnement sur toutes mes machines évite les surprises et les ajustements à chaque transition. Un enjeu de sécurité enfin : intégrer les politiques de durcissement (SSH notamment) dès l'installation initiale garantit qu'aucune machine ne reste exposée pendant la fenêtre temporelle qui sépare habituellement l'install d'un système et son durcissement manuel.
Les risques propres au projet sont à prendre au sérieux. Un script d'installation qui casse une étape peut laisser le système dans un état intermédiaire incohérent. Un script qui s'exécute sur des distributions différentes sans précautions peut provoquer des comportements inattendus. Une configuration de durcissement mal pensée peut me verrouiller hors de ma propre machine, notamment sur le volet SSH si la clé n'est pas correctement déployée avant la désactivation du mot de passe. Ces risques ont façonné mes choix techniques : idempotence, gestion d'erreur explicite, et tests systématiques en VM jetable avant tout déploiement sur une machine cible.
Étapes de réalisation
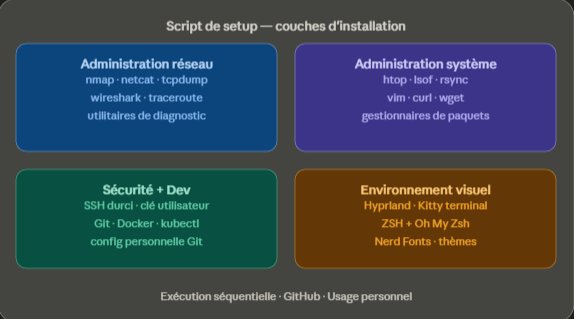
Les cinq couches d'installation du script, déployées dans un ordre logique de dépendance.
Choisir le langage, structurer le script, garantir l'idempotence
Le choix du langage a été le premier arbitrage. J'ai opté pour Python en première version, principalement parce que c'est mon langage le plus à l'aise et parce qu'il offre une gestion d'erreur structurée que Bash rend plus difficile. Cette décision a un revers que j'assume : Python n'est pas toujours présent sur un système fraîchement installé, surtout sur des distributions minimalistes. C'est pourquoi une version Bash est en cours de développement en parallèle, pour éliminer cette dépendance et garantir que le script peut tourner sur n'importe quel Linux dès le premier boot.
L'idempotence a été imposée comme contrainte de conception dès le départ. Le script peut être relancé plusieurs fois sans casser le système : avant chaque action, il vérifie si l'état cible est déjà atteint, et passe l'étape si c'est le cas. Concrètement, cela signifie vérifier qu'un paquet n'est pas déjà installé avant apt install, qu'une ligne de configuration n'est pas déjà présente avant de l'ajouter, qu'une clé SSH n'existe pas déjà avant d'en générer une nouvelle. Cette discipline transforme le script en outil réutilisable comme outil de mise à jour, pas seulement comme outil d'installation initiale.
Installer les utilitaires indispensables au diagnostic et à l'administration
La première couche déployée concerne les outils d'administration réseau, qui sont mes outils du quotidien dès qu'il s'agit d'analyser un trafic ou de déboguer une connectivité : nmap pour la cartographie réseau, netcat pour les tests de port et le tunneling rapide, tcpdump pour la capture en ligne de commande, wireshark pour l'analyse approfondie, traceroute, ainsi que les utilitaires de diagnostic courants (iproute2, iputils, dnsutils).
Les outils d'administration système suivent dans la même couche, par cohérence d'usage : htop pour la supervision interactive, lsof pour l'inspection des descripteurs de fichiers, rsync pour les synchronisations fiables, curl et wget pour les requêtes web, vim comme éditeur de référence, ainsi que les utilitaires de gestion de processus et de logs. Cette couche est la fondation sur laquelle s'appuient toutes les suivantes : sans ces outils, le diagnostic en cas de problème ultérieur devient compliqué.
Sécuriser l'accès distant dès l'installation initiale
Avant de pousser plus loin, le script applique automatiquement une politique de durcissement SSH. C'est une étape critique : un poste fraîchement installé reste vulnérable tant que les politiques par défaut ne sont pas durcies. Le script génère une nouvelle paire de clés pour mon utilisateur, ajoute ma clé publique aux authorized_keys, puis modifie sshd_config pour désactiver l'authentification par mot de passe, désactiver le login root direct et restreindre les algorithmes utilisés à ceux considérés comme sûrs.
L'ordre des opérations est déterminant ici. Désactiver l'authentification par mot de passe avant d'avoir déployé une clé fonctionnelle revient à se verrouiller hors de la machine. Le script implémente une séquence sécurisée : générer la clé, déployer la clé publique, tester l'authentification par clé en local, et seulement ensuite modifier sshd_config. Cette précaution est née d'un retour d'expérience douloureux pendant la phase de développement où je me suis effectivement verrouillé hors d'une VM de test, ce qui m'a fait perdre une heure de configuration mais m'a définitivement formé sur la prudence à appliquer.
Déployer Git, Docker, Kubernetes et les dépendances de projet
La troisième couche déploie les outils de développement et d'infrastructure qui sont indispensables à la quasi-totalité de mes projets. Git est installé avec ma configuration personnelle (user, email, signature, alias usuels). Docker est installé via le dépôt officiel pour disposer de la version à jour plutôt que celle parfois en retard des dépôts de distribution, avec son démon configuré et mon utilisateur ajouté au groupe docker. kubectl est installé pour interagir avec mes clusters Kubernetes de lab.
Les versions installées suivent une logique simple : dernière version stable pour les outils de développement, version recommandée par l'éditeur pour Docker, version compatible avec mon cluster Kubernetes courant pour kubectl. Cette approche m'a évité des incompatibilités quand je passe d'une machine à l'autre, car toutes ont la même base de versions.
Installer Hyprland, Kitty, Zsh, Nerd Fonts, et la couche qui m'a donné le plus de fil à retordre
La dernière couche d'installation concerne l'environnement visuel et personnel, et c'est de loin celle qui a posé le plus de problèmes techniques. J'installe Hyprland, un compositeur de fenêtres dynamique pour Linux basé sur Wayland, particulièrement adapté aux environnements de travail techniques avec son approche tiling. Mon terminal est Kitty, configuré avec mes raccourcis personnels, mes thèmes de couleurs et mes préférences d'affichage. Le shell par défaut est remplacé par Zsh, avec Oh My Zsh, mes thèmes et mes alias habituels. Les Nerd Fonts sont installées pour permettre l'affichage correct des icônes et glyphes utilisés par mon prompt et mes éditeurs.
La difficulté principale a concerné Hyprland sur Debian. Jusqu'à très récemment, Hyprland n'était pas disponible dans les dépôts officiels Debian, ce qui obligeait à le compiler depuis les sources avec ses nombreuses dépendances (wayland-protocols, libdrm, libinput, hyprlang, etc.). Cette compilation était fragile et longue, et l'aboutissement n'était pas garanti selon la version de Debian utilisée. À l'inverse, sur Arch, Hyprland est dans l'AUR et l'installation est triviale, ce qui explique en partie ma préférence personnelle pour Arch comme distribution principale.
L'autre point sensible est la compatibilité avec les drivers Nvidia. Hyprland a longtemps souffert de problèmes d'affichage avec les drivers propriétaires Nvidia : artefacts, écrans noirs, performances dégradées, instabilités lors de la mise en veille. Selon la génération de carte et la version du driver, le script pouvait produire un environnement parfaitement fonctionnel ou un environnement inutilisable. Depuis quelques mois, la situation s'est largement améliorée et l'installation se passe correctement tant que je ne modifie pas la configuration matérielle. Toute modification (changement de carte, mise à jour majeure de driver, switch entre GPU intégré et discret) déclenche encore aujourd'hui des petits ajustements et des tests pour vérifier que tout fonctionne.
Gérer Debian et Arch avec leurs gestionnaires de paquets respectifs
Le script supporte deux familles de distributions : Debian (avec apt) et Arch Linux (avec pacman et l'AUR via yay). La distinction est aujourd'hui passée en paramètre explicite à l'invocation du script, mais je travaille sur une détection automatique qui utilisera les standards habituels : lecture de /etc/os-release en priorité, et fallback sur la commande lsb_release -i si nécessaire. Cette évolution permettra de simplifier l'invocation et de réduire le risque d'erreur utilisateur en sélectionnant le mauvais profil.
Les packages installés sont mappés entre les deux écosystèmes via un fichier de correspondance simple, ce qui me permet de définir un outil une seule fois et de laisser le script choisir le nom de paquet adapté à la distribution cible.
Organisation et acteurs
Ce projet est entièrement individuel. Il n'implique aucun collaborateur externe, mais il bénéficie indirectement et largement de la communauté open source : une grande partie des outils, configurations et bonnes pratiques que le script automatise s'appuient sur des projets maintenus collectivement, dont mes dotfiles ne sont en pratique qu'un assemblage personnalisé.
L'inspiration méthodologique principale vient de la chaîne YouTube Dinkii, dont la vidéo de référence (lien plus haut) a donné le cadre structurel que mes premières briques disparates n'avaient pas. C'est un bon exemple de ce que peut apporter une bonne ressource pédagogique au bon moment : transformer des fragments épars en un projet cohérent.
Au-delà de Dinkii, je continue à m'enrichir des partages d'autres techniciens sur ma communauté Keybase et sur Twitter, qui publient régulièrement leurs propres configurations et donnent des idées pour améliorer la mienne.
Résultats
Pour moi, le résultat est très concret et directement mesurable. Une installation complète depuis un Linux vierge prend désormais moins d'une heure en quelques commandes, là où la même opération manuelle prenait facilement une demi-journée pour atteindre un niveau équivalent de finition. Le script a été utilisé en conditions réelles quatre fois à ce jour, sur des contextes variés : une réinstallation complète de mon poste principal, un nouvel ordinateur portable, deux machines virtuelles de lab. À chaque exécution, je retrouve mon environnement à l'identique, sans friction.
Le gain n'est pas seulement temporel. Il est aussi qualitatif : plus aucune friction lors d'une réinstallation, plus de temps perdu à chercher des configurations oubliées, plus de moments où je me dis "il faudrait que je remette tel alias, j'y penserai plus tard". Tout ce qui était dans ma tête est désormais dans le code, et le code ne perd rien.
Le script m'a également permis de mieux comprendre les dépendances entre les différents composants de mon environnement et de documenter mes propres choix techniques de manière structurée. Un script de setup, c'est en réalité une carte mentale de son propre environnement de travail rendue exécutable.
Lendemains du projet
Chaque utilisation du script déclenche une passe d'ajustement immédiatement après : ajout d'un nouvel outil que j'avais oublié d'intégrer, correction d'un comportement légèrement différent sur la nouvelle machine, mise à jour d'un alias devenu obsolète. Cette boucle de rétroaction permanente fait que chaque utilisation du script l'améliore pour la suivante. C'est exactement le principe d'un outil vivant, par opposition à un outil figé qu'on installe une fois pour toutes.
Le projet s'est étoffé continûment depuis la version initiale début 2025. La couche réseau a été enrichie, la couche système densifiée, le durcissement SSH affiné, et la couche environnement visuel est passée d'une simple installation de Zsh à toute la stack Hyprland + Kitty + Nerd Fonts. Le passage du mode "petites briques" au mode "outil cohérent" a été le saut de maturité le plus important, et il n'aurait pas eu lieu sans le déclic vidéo.
Plusieurs évolutions concrètes sont sur ma roadmap. La version Bash en cours de développement permettra d'éliminer la dépendance Python et d'utiliser le script sur n'importe quel Linux dès le premier boot. La détection automatique de distribution via /etc/os-release et lsb_release simplifiera l'invocation. Une modularisation par profils est aussi prévue : un profil orienté audit (outils offensifs), un profil orienté développement (langages, IDE), un profil orienté administration système (monitoring, outils d'infra), pour pouvoir adapter le déploiement au contexte d'usage de la machine cible.
À plus long terme, je réfléchis à une réécriture en Ansible ou NixOS qui apporterait une idempotence native sans avoir à la coder à la main, et qui pourrait aussi servir à provisionner des machines distantes. La publication sur GitHub en public reste un objectif, mais elle exigera de séparer rigoureusement les dotfiles génériques (publiables) des dotfiles sensibles (personnels, références à mon infrastructure). C'est un travail de séparation que je n'ai pas encore eu le temps de faire proprement.
Regard critique
Mes apports concrets sur ce projet sont de trois ordres. D'abord la discipline d'automatisation appliquée à mon propre poste, qui n'est pas naturelle pour un technicien : on automatise volontiers les serveurs des autres, beaucoup moins facilement son propre environnement de travail. Ensuite la capture de mes choix techniques en code versionné, qui transforme une connaissance tacite (ce que j'aime avoir sur un poste) en connaissance explicite et transférable. Enfin l'intégration du durcissement dès l'installation, qui fait passer la sécurité d'un sujet "à appliquer plus tard" à un sujet "déjà appliqué par défaut".
Ma valeur ajoutée mesurable est double. D'une part, un gain de temps direct mesurable à chaque utilisation : moins d'une heure pour un setup complet vs une demi-journée manuelle, sur quatre utilisations cela représente déjà plusieurs jours-homme économisés. D'autre part, une cohérence d'environnement entre toutes mes machines qui élimine les frictions de transition : je n'ai plus à me demander si telle commande va marcher ailleurs, parce que tout est identique partout.
Mes enseignements personnels sont marquants. Le plus important est probablement que documenter et automatiser ses propres habitudes de travail oblige à les questionner. En formalisant chaque choix dans un script, on réalise ce qui est vraiment utile, ce qui est superflu, et ce qui manque. C'est une forme de recul sur sa propre pratique qu'on n'a pas souvent l'occasion de prendre. Le second enseignement, plus pratique, est qu'un script imparfait qui automatise 70% du travail vaut infiniment mieux qu'une installation manuelle parfaite qui recommence à zéro à chaque fois. C'est le conseil que je donnerais à n'importe qui voudrait se lancer dans ce type de projet : ne pas attendre la version parfaite pour commencer.
Avec le recul, je vois aussi les limites du projet en l'état actuel. La maintenance est irrégulière : entre deux utilisations réelles du script, je ne le mets pas systématiquement à jour, ce qui veut dire que des versions vulnérables d'outils peuvent rester épinglées sans que je le sache. Cette dette de sécurité est inhérente à un projet personnel sans CI/CD ni revue régulière, et elle constitue précisément l'un des arguments pour la migration vers Ansible ou NixOS prévue. Par ailleurs, le caractère personnel du dépôt limite la valeur communautaire du projet : il ne profite à personne d'autre que moi, alors qu'un dépôt public aurait pu servir à d'autres techniciens. C'est un compromis assumé, mais c'est un compromis.
Compétences rattachées
Ce projet mobilise principalement des compétences techniques, tout en s'appuyant sur des qualités personnelles fortes. Sur le volet technique, il illustre directement le Tooling & Scripting dans son aspect outil structuré et idempotent (par opposition au script jetable), la Configuration Système par la maîtrise fine des fichiers et processus configurés automatiquement (SSH, gestionnaires de paquets, dotfiles), et Git par la mise en versionnement de l'ensemble. Sur le volet humain, il met en avant l'Autonomie de bout en bout sur un projet personnel et la capacité à Faire preuve d'initiative en construisant son propre outillage plutôt qu'en attendant qu'une solution toute faite existe.