Outil de déploiement automatisé
// En une phrase
Construire volontairement un outil similaire à Ansible pour comprendre les mécanismes d'automatisation par SSH de l'intérieur, l'utiliser concrètement sur 30 à 40 endpoints en alternance, puis en reprendre les acquis dans une version Python publiée publiquement qui sert encore aujourd'hui de terrain d'apprentissage.
Présentation
Avant de connaître Ansible, j'avais un problème très concret : je gérais un grand nombre de machines virtuelles, aussi bien dans le cadre de mon alternance chez Valesys que dans mon lab personnel, et chaque nouvelle VM imposait une série de configurations initiales répétitives. Mise à jour du système, installation des utilitaires réseau, déploiement d'agents, configuration SSH, ajout d'utilisateurs, ces tâches identiques étaient réalisées manuellement, encore et encore.
Plutôt que de chercher immédiatement une solution existante, j'ai fait le choix délibéré de construire mon propre outil. Non par méconnaissance d'Ansible, dont j'avais entendu parler, mais par volonté de comprendre de l'intérieur ce que ce type d'outil fait réellement. C'est cette démarche qui a donné naissance au projet, dans une première version Bash + YAML utilisée chez Valesys, puis dans une réécriture Python publique nommée SQC (SSH Quick Config) hébergée sur mon GitHub.
github.com/ninko0/SQCObjectifs, contexte et enjeux
L'objectif était de disposer d'un outil léger, portable et flexible, capable de déployer automatiquement des configurations et des outils sur un ou plusieurs endpoints distants, en utilisant uniquement une connexion SSH comme prérequis. Pas d'agent à installer côté cible, pas de dépendance lourde, juste un binaire sur la machine de contrôle et un fichier de configuration.
L'enjeu était double. D'un côté, gagner du temps sur des tâches répétitives et réduire les erreurs humaines liées aux configurations manuelles : sur 30 à 40 endpoints, la moindre commande oubliée se traduit par une incohérence qui ressort plus tard en incident. De l'autre, mieux comprendre les mécanismes sous-jacents à l'automatisation de déploiement (sessions SSH parallèles, idempotence, gestion d'erreurs en chaîne, format de configuration), ce qui s'est révélé particulièrement formateur pour la suite quand j'ai abordé Ansible et AWX avec une compréhension déjà solide des concepts.
Les risques propres à un tel outil sont nombreux et m'ont guidé dans les choix de conception. Une commande lancée sur plusieurs machines simultanément peut provoquer des dégâts multipliés par le nombre de cibles si elle est mal pensée. Une session SSH qui tombe en cours de déploiement peut laisser un système dans un état intermédiaire incohérent. Un script qui s'exécute différemment selon la distribution cible peut produire des résultats imprévisibles. Ces risques expliquent pourquoi le projet est resté volontairement limité à un usage personnel et à un lab, et n'a jamais été déployé sur des infrastructures critiques sans supervision directe.
Étapes de réalisation
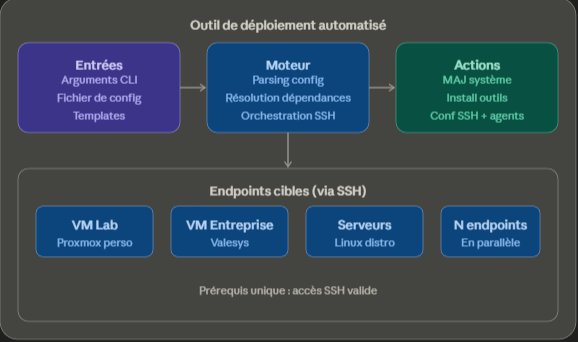
Architecture de l'outil : entrées (CLI ou fichier de configuration), moteur central, et endpoints cibles via SSH.
Définir le périmètre fonctionnel et les choix techniques de la première version
La conception a démarré par l'identification des besoins récurrents sur les VM que je déployais chez Valesys et en lab : quelles configurations revenaient systématiquement sur chaque nouvelle VM, quels outils devaient être présents par défaut, et quelles actions devaient rester optionnelles selon le contexte. Cette analyse a donné un périmètre clair : mises à jour système, installation de paquets, création d'utilisateurs et de clés SSH, durcissement de sshd_config, configuration réseau via netplan, déploiement d'agents (Wazuh, Zabbix), installation de Docker.
Pour le langage de cette première version, j'ai retenu Bash par souci de portabilité maximale : Bash est présent sur toute distribution Linux fraîchement installée, sans dépendance à ajouter. Le format de configuration choisi a été YAML, déjà standard de fait dans l'écosystème DevOps, lisible par un humain et facilement parseable. Cette première version a été développée et utilisée en interne chez Valesys, hébergée sur le GitLab interne de l'entreprise auquel je n'ai plus accès depuis la fin de mon contrat. Le code original Bash de cette version est donc perdu, ce qui est un point de fragilité du projet sur lequel je reviendrai dans le regard critique.
Définir un format YAML simple et extensible pour décrire les endpoints
Le fichier de configuration suivait un schéma volontairement simple, inspiré du format inventory d'Ansible que je découvrais en parallèle. Un exemple typique ressemblait à ceci :
endpoints:
- host: srv-web-01.lab.local
user: deploy
actions:
- apt_update
- install_packages: [nginx, certbot, fail2ban]
- ssh_hardening
- add_user: { name: nicolas, ssh_key: ~/.ssh/id_ed25519.pub }
- host: srv-monitoring-01.lab.local
user: deploy
actions:
- apt_update
- install_packages: [zabbix-agent, wazuh-agent]
- configure_agent: { server: 192.168.10.5 }Cette structure permet de lister plusieurs endpoints avec, pour chacun, les actions à appliquer selon une syntaxe qui se rapproche de celle des playbooks Ansible. L'outil parse ce fichier au démarrage, valide la cohérence des entrées, puis déploie machine par machine. Le format est simple mais suffisamment expressif pour couvrir la grande majorité des cas d'usage que je rencontrais.
Structurer l'outil pour permettre l'ajout de nouvelles fonctionnalités sans toucher au cœur
L'architecture a été pensée pour être facilement extensible. Ajouter une nouvelle action (un nouvel outil à installer, une nouvelle configuration à appliquer) ne nécessite pas de modifier le cœur du programme. Chaque action est implémentée comme un script séparé dans un dossier dédié, suivant une convention de nommage et une signature commune. Le moteur principal détecte automatiquement ces scripts et les rend disponibles via le fichier de configuration YAML.
Cette structure modulaire permet à une personne extérieure de contribuer à l'outil sans avoir besoin de comprendre l'ensemble du code : il suffit de comprendre la convention d'un script d'action pour en écrire un nouveau. C'est exactement le principe que j'apprécierais retrouver plus tard dans les modules Ansible.
CLI rapide pour un endpoint, fichier de configuration pour plusieurs
L'outil propose deux modes d'utilisation distincts, adaptés à des cas d'usage différents. Le premier mode permet de cibler un endpoint unique directement en ligne de commande, avec des options passées en arguments pour définir ce qui doit être installé ou configuré. Idéal pour les opérations rapides et ponctuelles, type "je veux juste installer Docker sur cette nouvelle VM".
Le second mode accepte un fichier de configuration YAML structuré dans lequel on liste plusieurs endpoints avec leurs actions respectives. Idéal pour le déploiement industrialisé d'un lab complet, ou pour reproduire à l'identique une configuration sur plusieurs machines. C'est ce second mode qui a été le plus utilisé en pratique, notamment pour préparer rapidement les VM nécessaires aux différents projets en lab.
Anticiper les pannes réseau, les redémarrages de kernel et la dépendance ordre des services
L'expérience opérationnelle a fait remonter plusieurs problèmes spécifiques aux déploiements SSH à distance qui ne sont pas évidents quand on conçoit l'outil sur papier. La connectivité Internet est un point sensible : si la machine cible perd l'accès aux dépôts pendant un apt update, le déploiement échoue silencieusement ou laisse des paquets dans un état incohérent. Il faut gérer le timeout, le retry, et la reprise après erreur.
Le redémarrage de kernel est l'autre point délicat. Certaines mises à jour (kernel, librairies systèmes critiques) imposent un redémarrage pour être pleinement effectives. Si le déploiement enchaîne plusieurs actions dont l'une nécessite un reboot, il faut séquencer correctement : ne pas tenter d'installer un service qui dépend d'un kernel non encore actif, attendre que la machine soit réellement remontée avant de poursuivre, gérer le cas où la machine ne remonte pas (échec à signaler clairement).
Enfin, l'ordre d'installation et de mise à jour des services doit être maîtrisé. Installer un agent Wazuh avant la mise à jour système peut produire des conflits de dépendances. Configurer un service réseau avant que les interfaces ne soient correctement provisionnées génère des erreurs difficiles à diagnostiquer. Ces séquencements ont été appris par la pratique, et chaque échec a alimenté la robustesse de l'outil sur la version suivante.
Reprendre les acquis dans une version publique pour les valoriser sur GitHub
Après mon contrat Valesys, j'ai entamé une réécriture publique en Python sous le nom SQC (SSH Quick Config), hébergée sur GitHub. Cette réécriture poursuit deux objectifs : conserver les acquis de la version Bash perdue, et publier un projet vérifiable dans mon portfolio open source, accessible à tout évaluateur ou employeur.
La version actuelle implémente déjà plusieurs actions opérationnelles : apt update et upgrade du système, ajout d'utilisateurs, installation d'une liste de paquets apt, git clone d'une liste d'outils, modification de la configuration SSH, et changement de netplan. Une roadmap claire est documentée dans le README du dépôt avec les fonctionnalités à venir : installation et configuration d'Apache avec ajout de certificats X.509, création de certificats X.509 auto-signés, gestion utilisateurs et groupes en une seule commande, installation de Zsh avec Oh My Zsh et bascule du shell par défaut.
Je n'ai pas caché les limites actuelles du projet dans le README public : le code y est qualifié de "spaghetti par moments", le projet est explicitement marqué "in construction", et j'ai documenté un bug connu sur la fonction netplan qui peut provoquer des collisions d'IP si elle est mal utilisée. Cette transparence n'est pas une faiblesse, c'est une discipline de contributeur open source : ne pas faire passer un projet pour plus mature qu'il ne l'est, c'est respecter le temps des éventuels utilisateurs qui s'y intéresseront.
Organisation et acteurs
Ce projet a été développé seul, dans le cadre de mon alternance chez Valesys et de mon lab personnel. La version originale Bash a été hébergée sur le GitLab interne de Valesys, auquel je n'ai plus accès aujourd'hui. Les utilisateurs directs de cette version originale étaient principalement moi-même, dans les deux contextes (entreprise et lab personnel).
La version publique Python SQC est hébergée sur mon GitHub avec 10 commits et 2 stars à ce jour. La traction publique reste modeste, mais le projet est vérifiable, ce qui le distingue de la version Valesys perdue. Cette différence de statut entre version privée et version publique est devenue chez moi une discipline : ce qui n'est pas accessible publiquement ne peut pas être considéré comme une réalisation portable.
Résultats
Pour Valesys et mon lab personnel, l'outil a permis de réduire significativement le temps de mise en place des configurations initiales sur les VM. Des tâches qui prenaient auparavant plusieurs dizaines de minutes par machine, répétées manuellement, sont devenues une affaire de quelques secondes une fois le fichier de configuration prêt. Sur les 30 à 40 endpoints déployés au total, le gain cumulé représente plusieurs journées de travail économisées sur la durée de mon alternance.
Pour moi, le résultat dépasse largement le gain de temps direct. Construire cet outil m'a permis de comprendre concrètement ce que signifie concevoir un outil destiné à être réutilisé et modifié dans le temps. La contrainte d'extensibilité que je m'étais fixée dès le départ a obligé à réfléchir à la structure du code différemment de ce que je faisais habituellement : interfaces stables, conventions partagées, séparation entre moteur et plugins. Ce sont exactement les concepts que j'ai retrouvés ensuite dans Ansible, et que j'ai pu m'approprier infiniment plus vite parce que je les avais déjà digérés à ma propre échelle.
Lendemains du projet
L'outil a été utilisé en routine pendant la durée de mon alternance chez Valesys, et adapté en continu pour intégrer de nouveaux besoins (nouveaux outils à déployer, nouvelles configurations à automatiser). Cette boucle d'usage et d'amélioration a fait évoluer l'outil d'un script ponctuel à un outil structuré que je pouvais relancer en confiance.
Peu après la version Valesys, j'ai commencé à travailler sérieusement avec Ansible, puis avec GitLab CI et AWX pour l'orchestration. La compréhension acquise en construisant mon propre outil m'a permis d'appréhender ces technologies bien plus rapidement que si je les avais découvertes sans ce bagage. Savoir ce qu'un outil fait de l'intérieur change profondément la façon dont on l'utilise : on n'est plus dans la consommation passive d'un produit, on est dans la compréhension active d'un mécanisme.
Le projet personnel en lui-même a alors progressivement laissé sa place à ces solutions plus matures pour mes usages opérationnels, ce qui est un cycle de vie sain pour un outil d'apprentissage. La réécriture publique SQC en Python a continué d'exister en parallèle, plus comme exercice de versionnement public et de progression personnelle que comme outil opérationnel.
Aujourd'hui chez Paritel, j'évolue dans un contexte où Ansible est utilisé en production pour l'orchestration des outils de cybersécurité, hébergés sur le GitLab interne de l'entreprise. La compréhension de fond que j'ai construite avec mon propre outil me sert directement à analyser et comprendre les playbooks utilisés par l'équipe, sans avoir à me former from scratch à l'écosystème.
Plusieurs pistes d'évolution restent ouvertes sur SQC. La finalisation de la roadmap publique documentée dans le README (Apache+X509, certs auto-signés, gestion users/groupes, install Zsh) est un objectif court terme. Au-delà, j'envisage de réécrire SQC dans d'autres langages à des fins pédagogiques personnelles : une version Go pour explorer la concurrence native, une version Rust pour le ramener à ses fondamentaux système. Ce ne sera jamais un outil destiné à remplacer Ansible ou AWX qui restent objectivement bien plus performants et mieux maintenus, mais ce restera un excellent terrain d'expérimentation pour me confronter à de nouveaux langages avec un cahier des charges que je maîtrise déjà.
Regard critique
Mes apports concrets sur ce projet sont de trois ordres. D'abord la démarche assumée de réinventer la roue à des fins d'apprentissage, plutôt que de consommer un outil mature sans en comprendre les mécanismes. Cette approche n'est pas universellement recommandable, mais quand elle est faite consciemment et avec un objectif pédagogique clair, elle apporte une profondeur de compréhension qu'aucun tutoriel ne donne. Ensuite la conception extensible dès le départ, qui a structuré ma façon de penser le code bien au-delà de ce projet. Enfin la discipline de transparence open source sur le repo SQC public : assumer les limites actuelles dans le README plutôt que de les masquer est un choix qui m'a coûté en ego mais qui correspond à mes valeurs sur le partage de code.
Ma valeur ajoutée mesurable est double. Sur le plan opérationnel chez Valesys, des dizaines d'heures économisées en routine de déploiement sur 30 à 40 endpoints, sans erreur humaine introduite. Sur le plan personnel, une maîtrise accélérée d'Ansible et d'AWX ensuite, parce que les concepts d'inventory, de playbook, de modules et d'idempotence étaient déjà digérés à ma propre échelle. Cette accélération a été un véritable avantage compétitif quand je suis entré sur les sujets DevOps avancés chez Paritel.
Mes enseignements personnels sont nombreux et durables. Le plus important est probablement que réinventer la roue a parfois beaucoup de valeur, à condition de le faire consciemment et dans un objectif d'apprentissage. Je ne recommande pas de reconstruire Ansible pour une utilisation en production, ce serait absurde. En revanche, construire un outil similaire à plus petite échelle pour en comprendre les mécanismes est l'un des exercices les plus formateurs que j'aie faits dans ma jeune carrière. Le second enseignement est la nécessité d'investir dès le départ dans une gestion d'erreurs robuste et des logs lisibles. Ce sont les deux points qui ont montré leurs limites lorsque l'outil a commencé à être utilisé sur un nombre croissant de machines simultanément, et c'est exactement ce que les outils matures font très bien et qui justifie leur maturité.
Avec le recul, je vois aussi plusieurs limites importantes du projet. La perte de la version originale Bash hébergée sur le GitLab interne de Valesys est un point de fragilité que j'ai retenu : ce qui n'est pas hébergé sur ses propres ressources n'est pas une réalisation portable, peu importe sa qualité. La limitation aux distributions Debian-based de la version Python publique restreint son adoption potentielle. Le statut "spaghetti code" assumé dans le README est honnête mais montre aussi qu'un projet d'apprentissage ne devient pas automatiquement un projet de production : il faudrait un travail de refactor sérieux pour que SQC dépasse son statut actuel. Et enfin, Ansible et AWX restent objectivement plus performants et mieux maintenus, ce qui rend SQC pédagogiquement précieux mais opérationnellement secondaire. C'est une lucidité que j'assume pleinement.
Compétences rattachées
Ce projet mobilise principalement des compétences techniques transverses. Sur le volet technique, il illustre directement le Tooling & Scripting dans son aspect outil structuré et extensible (par opposition au script jetable), la Configuration Système par la connaissance fine des actions automatisées (apt, SSH, netplan, users, agents) et l'Administration Réseau par la maîtrise du protocole SSH comme socle d'orchestration. Sur le volet humain, il met en avant l'Autonomie nécessaire pour construire un outil de A à Z sans encadrement et la capacité à Faire preuve d'initiative, illustrée par le choix volontaire de construire avant d'utiliser pour comprendre de l'intérieur.